Why Formalizing Requirements Matters in Model-Driven Manufacturing: How LLMs Help (Part 1/5)
Have you ever read a requirement like this and thought: “Okay… but what exactly are we supposed to build?”
“The user wants the robot to be accurate enough to pick small components reliably…”
“The user expects the robot to reach any point within a circular workspace of around 300 mm in radius…”
They sound reasonable. They also hide the usual problems: vague terms, missing conditions, unclear verification, and inconsistent wording. And in Model-Based Systems Engineering (MBSE), that becomes expensive later, because requirements are the starting point for traceability, design decisions, and testing.
This is Part 1/5 of a blog series based on our work-in-progress paper and the prototype we are building: turning user needs into clearer, more consistent, more verifiable system requirements, then exporting them into a SysML v2-compatible form.
Why Requirements Engineering becomes painful in manufacturing projects
In production system projects, unclear requirements don’t hurt when they’re written. They hurt when the system is being built, integrated, and tested. That’s when teams end up redesigning fixtures, rewiring panels, re-tuning motion profiles, or adding safety measures under time pressure, because the original intent was not stated in a testable way.
MBSE helps manage this complexity using frameworks like the V-Model (linking requirements to verification/validation) and RFLP (Requirements → Functional → Logical → Physical). But both still rely on the same fragile starting point: stakeholders express needs in free-form language, and engineers must translate that into consistent, measurable system requirements at scale.
So the practical question is:
How do we convert messy stakeholder input into system requirements that are clearer, more consistent, and more verifiable, without spending weeks rewriting everything manually?
The idea in one sentence
Build an assistant that takes informal requirements, checks them against requirement-writing rules, produces a transparent violation report, rewrites for compliance, and exports the refined requirements into a SysML v2-compatible representation.
What we built (high level)
The artifact is an LLM-based assistant, guided by requirement-writing rules from INCOSE and requirement classification aligned with IREB.
It does four main jobs:
Classifies each statement into requirement types (IREB-aligned):
Functional (what it should do)
Quality (how well it should perform)
Constraint (limits such as technical/organizational factors)
Checks rule violations using INCOSE-aligned writing rules and generates a violation report (e.g., vague terms, missing conditions, passive voice)
Rewrites for compliance, using the violation report as input, so the rewrite is traceable to specific issues
Serializes results for MBSE, storing structured requirement data in JSON and generating a SysML v2–compatible textual representation (via KerML) that can be imported/validated in SysML v2 tooling (e.g., SysON).
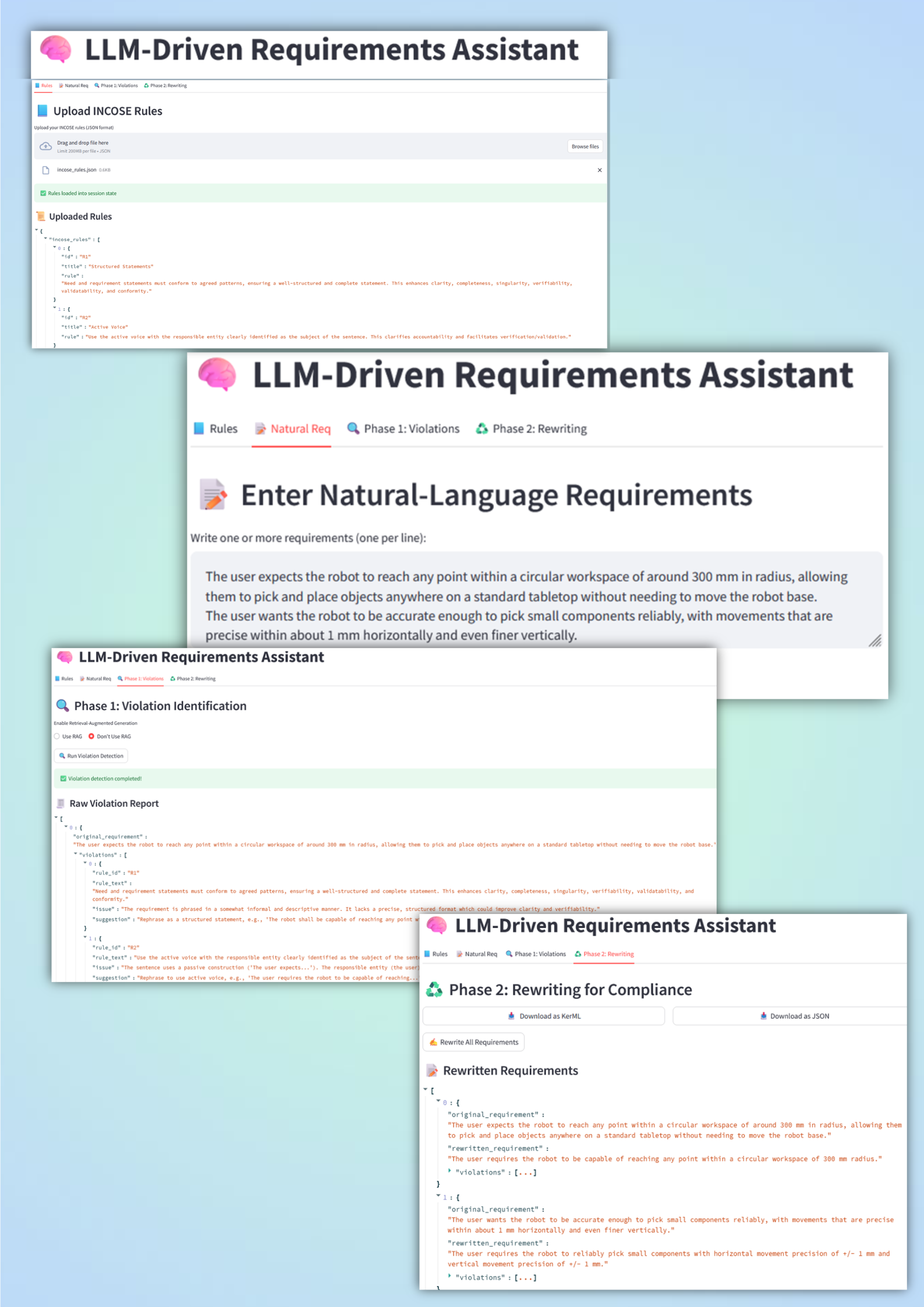
There’s also a lightweight UI: a Streamlit app where users upload requirements, review violations, accept rewrites, and export JSON or SysML v2 models.
The workflow (the part you can picture in your head)
Think of it as a two-pass process:
Phase 1: Violation Identification
For each requirement, the assistant generates a structured violation report that:
references the rule
highlights the problematic phrase
suggests how to improve it
This matters because it keeps the process transparent: you can see why something was flagged.
Phase 2: Rewriting for Compliance
Then the assistant rewrites the requirement using that report. The flow supports a human-in-the-loop approach: accept the rewrite automatically, or intervene when context matters.
The SysML v2 angle:
Once the requirements are refined, each one is enriched with a small set of structured attributes, such as a unique identifier, an alias, a category, and the final textual content.
This structured representation is first stored in JSON and then converted into SysML v2–compatible text so that the requirements can be imported into SysML v2 modeling workflows and used for traceability and downstream engineering activities.
The case study used to test the approach
To keep things grounded, we demonstrate the approach using an Arduino-based SCARA robot for tabletop pick-and-place tasks.
Stakeholder needs were gathered from:
educators (extensibility, documentation for teaching)
engineers (mechanical design, systems engineers, requirements engineers)
The assistant runs on Claude 3 Haiku via the Claude API, processes these stakeholder statements, and produces a SysML v2-compatible output. The SysML v2 output is validated by loading it in the SysON tool.
The honest challenges (and why this series exists)
This is where things get interesting, because it’s not “LLM magic solves RE”.
Challenge 1: Token cost vs coverage
Checking every requirement against all rules can get expensive. So the system includes an option for RAG: Retrieve only the most relevant rules using vector embeddings and a FAISS similarity index (top-k), then include those rules in the prompt. This saves cost, but risks missing edge-case violations.
Challenge 2: Some rules need human judgment or project context
Not every rule can be applied reliably without context. To improve outcomes, context such as glossaries, unit conventions, and template patterns can be included, while ambiguous cases are flagged for human review.
Challenge 3: Adoption depends on compatibility
Accuracy isn’t enough. The assistant also needs to produce outputs that can fit existing workflows, hence the focus on structured data, SysML export, and validation in SysML v2 tooling.
What’s coming in the next parts
In Part 2, we’ll zoom in on a practical question:
Do we really need an LLM to detect every rule violation?
We’ll show how a hybrid approach can reduce LLM calls by combining:
deterministic logic checks
lightweight NLP
and the LLM only where it adds real value (rewriting, ambiguity resolution, suggestions)
In Part 3, we’ll cover how predefined requirement patterns, glossaries, standard values, and TBD/TBC handling improve consistency and reduce ambiguity.
Finally, exporting SysML v2 text is useful, but real industrial projects often depend on requirement management tooling such as DOORS / Polarion / Jira.
”But can this be used without replacing your existing tools?”
In Part 4, we’ll propose a practical integration approach to make the workflow compatible with those toolchains.
A quick question for you (so this isn’t a one-way post)
What’s the most repetitive part of your requirements workflow that you’d want to automate?
Is it (1) rule checking, (2) rewriting, (3) traceability/IDs, or (4) exporting into tools like DOORS/Polarion/Jira?
I'd especially love to hear from anyone who is looking to integrate AI-assisted workflows with requirements management tools like DOORS, Polarion ALM, or Jira. Feel free to drop your thoughts below:
If you’re curious about the implementation details, here are a few visual snapshots of the pipeline and prototype UI.

A quick note: I used Claude to help with the flow and structure of this post. But every idea here is mine, and I read (and meant) every word.